Highlights 🎉
Jan v0.6.6 delivers significant improvements to the llama.cpp backend, introduces Hugging Face as a built-in provider, and brings smarter model management with auto-unload capabilities. This release also includes numerous MCP refinements and platform-specific enhancements.
🚀 Major llama.cpp Backend Overhaul
We’ve completely revamped the llama.cpp integration with:
- Smart Backend Management: The backend now auto-updates and persists your settings properly
- Device Detection: Jan automatically detects available GPUs and hardware capabilities
- Direct llama.cpp Access: Models now interface directly with llama.cpp (previously hidden behind Cortex)
- Automatic Migration: Your existing models seamlessly move from Cortex to direct llama.cpp management
- Better Error Handling: Clear error messages when models fail to load, with actionable solutions
- Per-Model Overrides: Configure specific settings for individual models
🤗 Hugging Face Cloud Router Integration
Connect to Hugging Face’s new cloud inference service:
- Access pre-configured models running on various providers (Fireworks, Together AI, and more)
- Hugging Face handles the routing to the best available provider
- Simplified setup with just your HF token
- Non-deletable provider status to prevent accidental removal
- Note: Direct model ID search in Hub remains available as before
🧠 Smarter Model Management
New intelligent features to optimize your system resources:
- Auto-Unload Old Models: Automatically free up memory by unloading unused models
- Persistent Settings: Your model capabilities and settings now persist across app restarts
- Zero GPU Layers Support: Set N-GPU Layers to 0 for CPU-only inference
- Memory Calculation Improvements: More accurate memory usage reporting
🎯 MCP Refinements
Enhanced MCP experience with:
- Tool approval dialog improvements with scrollable parameters
- Better experimental feature edge case handling
- Fixed tool call button disappearing issue
- JSON editing tooltips for easier configuration
- Auto-focus on “Always Allow” action for smoother workflows
📚 New MCP Integration Tutorials
Comprehensive guides for powerful MCP integrations:
- Canva MCP: Create and manage designs through natural language - generate logos, presentations, and marketing materials directly from chat
- Browserbase MCP: Control cloud browsers with AI - automate web tasks, extract data, and monitor sites without complex scripting
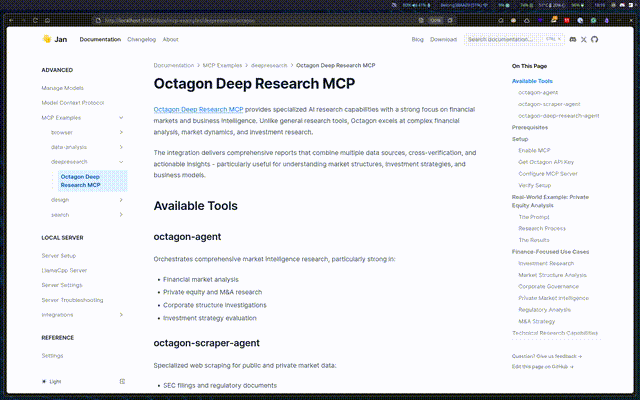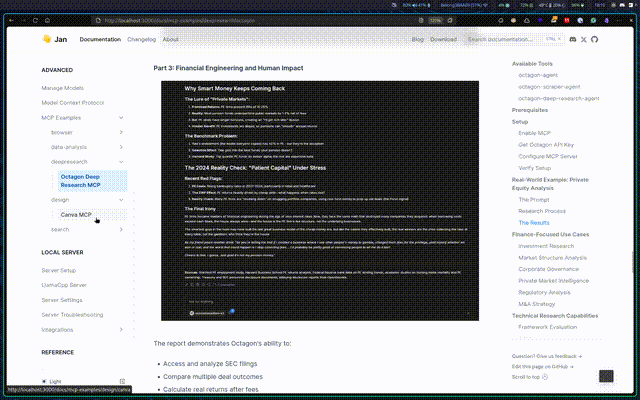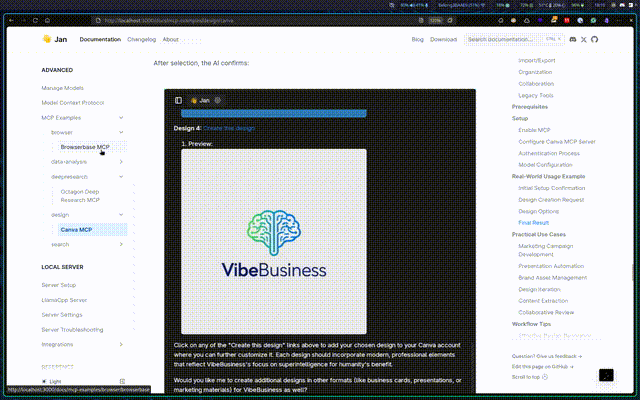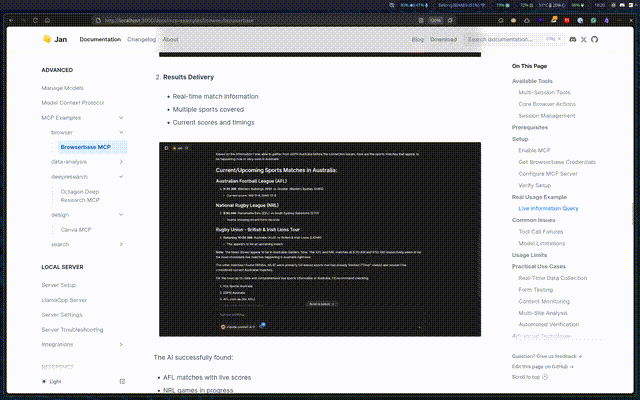
- Octagon Deep Research MCP: Access finance-focused research capabilities - analyze markets, investigate companies, and generate investment insights
🖥️ Platform-Specific Improvements
Windows:
- Fixed terminal windows popping up during model loading
- Better process termination handling
- VCRuntime included in installer for compatibility
- Improved NSIS installer with app running checks
Linux:
- AppImage now works properly with newest Tauri version and it went from almost 1GB to less than 200MB
- Better Wayland compatibility
macOS:
- Improved build process and artifact naming
🎨 UI/UX Enhancements
Quality of life improvements throughout:
- Fixed rename thread dialog showing incorrect thread names
- Assistant instructions now have proper defaults
- Download progress indicators remain visible when scrolling
- Better error pages with clearer messaging
- GPU detection now shows accurate backend information
- Improved clickable areas for better usability
🔧 Developer Experience
Behind the scenes improvements:
- New automated QA system using CUA (Computer Use Automation)
- Standardized build process across platforms
- Enhanced error stream handling and parsing
- Better proxy support for the new downloader
- Reasoning format support for advanced models
🐛 Bug Fixes
Notable fixes include:
- Factory reset no longer fails with access denied errors
- OpenRouter provider stays selected properly
- Model search in Hub shows latest data only
- Temporary download files are cleaned up on cancel
- Legacy threads no longer appear above new threads
- Fixed encoding issues on various platforms
Breaking Changes
- Models previously managed by Cortex now interface directly with llama.cpp (automatic migration included)
- Some sampling parameters have been removed from the llama.cpp extension for consistency
- Cortex extension is deprecated in favor of direct llama.cpp integration
Coming Next
We’re working on expanding MCP capabilities, improving model download speeds, and adding more provider integrations. Stay tuned!
Update your Jan or download the latest.
For the complete list of changes, see the GitHub release notes.